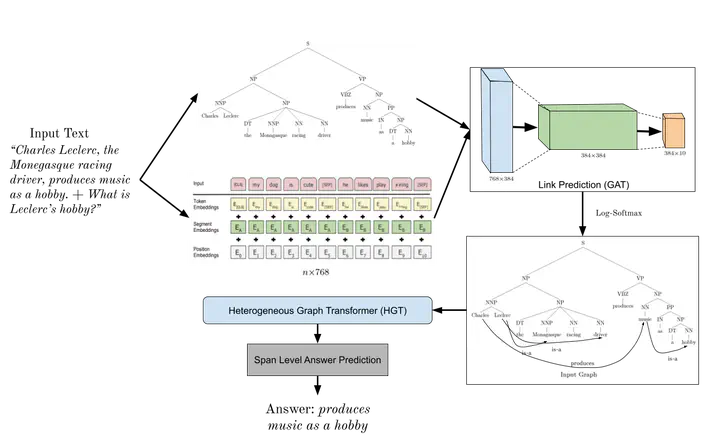
This project tackles the challenge of extractive question answering (QA), where the goal is to find a precise span of text from a passage that answers a given question. Traditional models often rely on deep language representations but may overlook the underlying syntactic and semantic structure of the context. By addressing this gap, the project aims to create more interpretable and linguistically aware QA systems that can better understand how information is organized and related within text.
To achieve this, we first parse each context passage into a constituency tree using a stack Bi-LSTM, forming the backbone of a graph representation. We then enrich this graph with semantic relationships predicted by a knowledge graph link prediction model. The combined structure is processed by a heterogeneous graph transformer integrating both syntactic and semantic cues for answer extraction. This approach allows for more explainable reasoning and provides a structured way to incorporate external knowledge into the QA process.
Min-Yen Kan
Associate Professor
WING lead; interests include Digital Libraries, Information Retrieval and Natural Language Processing.