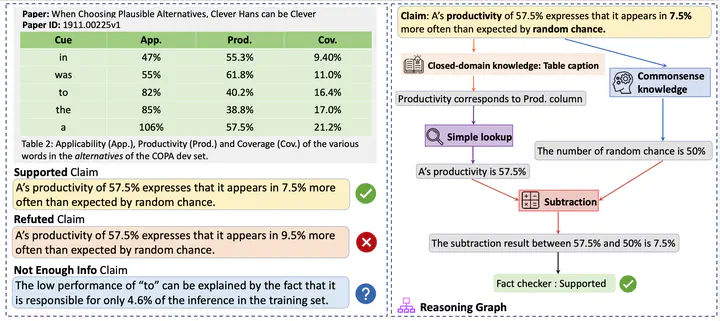
 Example from SCITAB showing a claim and its reasoning process.
Example from SCITAB showing a claim and its reasoning process.SCITAB was developed to fill the gap in scientific fact-checking benchmarks by incorporating claims derived from actual scientific papers rather than crowd-sourced ones. These claims require multi-step reasoning to verify against evidence in tables. The dataset was created using a human–model collaboration approach, where real-world claims were filtered, counterclaims were generated using InstructGPT, and all claims were manually verified by expert annotators.
The dataset has been extensively evaluated with state-of-the-art models, including TAPAS, TAPEX, Vicuna, and GPT-4, revealing that existing table-based models struggle with SCITAB. Only GPT-4 shows notable improvements, highlighting the dataset’s challenge and potential for advancing research in table-based reasoning.
SCITAB was presented at EMNLP 2023, and the dataset is publicly available for further research. Researchers interested in compositional reasoning, table fact-checking, and model robustness are encouraged to explore SCITAB and contribute to its future developments.
Min-Yen Kan
Associate Professor
WING lead; interests include Digital Libraries, Information Retrieval and Natural Language Processing.