 Figure from Li et al. (2025).
Figure from Li et al. (2025).Abstract
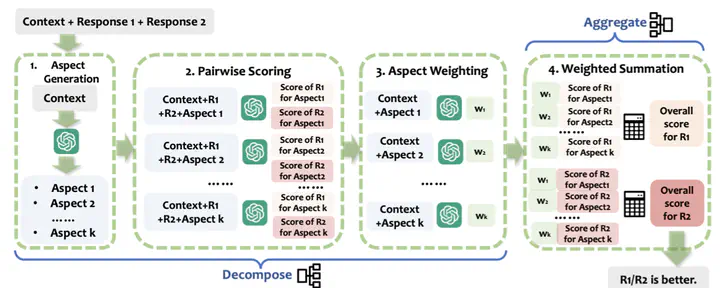
The acceleration of Large Language Models (LLMs) research has opened up new possibilities for evaluating generated text. Though LLMs serve as scalable and economical evaluators, how reliable these evaluators is still under-explored. Prior research efforts in the meta-evaluation of LLMs as judges limit the prompting of an LLM to a single use to obtain a final evaluation decision. They then compute the agreement between LLMs’ outputs and human labels. This lacks interpretability in understanding the evaluation capability of LLMs. In light of this challenge, we propose DnA-Eval, which breaks down the evaluation process into decomposition and aggregation stages based on pedagogical practices. Our experiments show that it not only provides a more interpretable window for how well LLMs evaluate, but also leads to improvements up to 39.6% for different LLMs on a variety of meta-evaluation benchmarks.
Minzhi Li (Ella)
A*STAR Doctoral Student (Aug ‘22)
Co-Supervised by Nancy F. Chen and Shafiq Joty
PhD Candidate August 2022 Intake
Min-Yen Kan
Associate Professor
WING lead; interests include Digital Libraries, Information Retrieval and Natural Language Processing.