 Setup of NNOSE nearest-neighbor occupational skill extraction from Zhang et al. (2024).
Setup of NNOSE nearest-neighbor occupational skill extraction from Zhang et al. (2024).Abstract
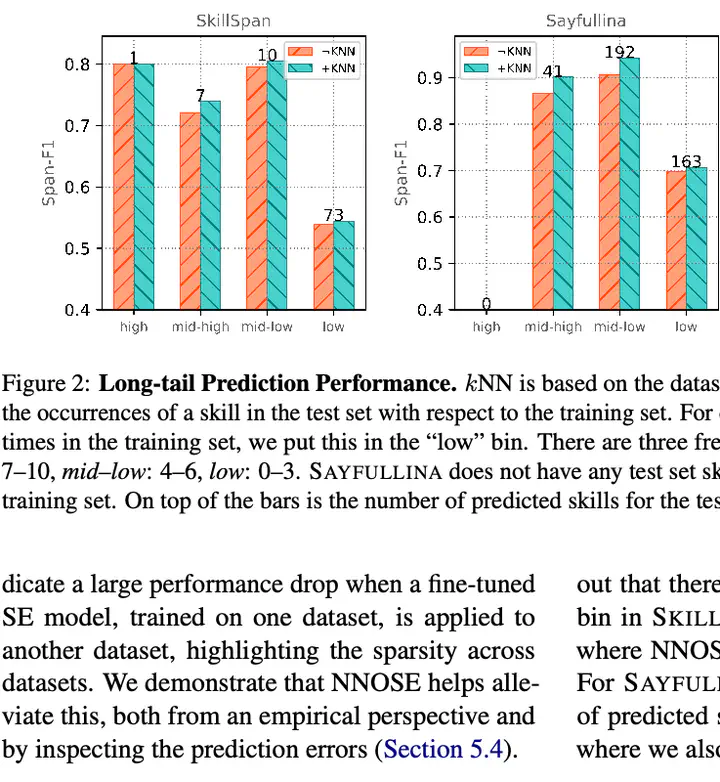
The labor market is changing rapidly, prompting increased interest in the automatic extraction of occupational skills from text. With the advent of English benchmark job description datasets, there is a need for systems that handle their diversity well. We tackle the complexity in occupational skill datasets tasks—combining and leveraging multiple datasets for skill extraction, to identify rarely observed skills within a dataset, and overcoming the scarcity of skills across datasets. In particular, we investigate the retrieval-augmentation of language models, employing an external datastore for retrieving similar skills in a dataset-unifying manner. Our proposed method, textbfNearest textbfNeighbor textbfOccupational textbfSkill textbfExtraction (NNOSE) effectively leverages multiple datasets by retrieving neighboring skills from other datasets in the datastore. This improves skill extraction textitwithout additional fine-tuning. Crucially, we observe a performance gain in predicting infrequent patterns, with substantial gains of up to 30% span-F1 in cross-dataset settings.
Min-Yen Kan
Associate Professor
WING lead; interests include Digital Libraries, Information Retrieval and Natural Language Processing.