Here is the listing of projects which were completed by WING members before 2011.
If you’re looking for a brief introduction of research in the WING group, check out these presentation slides, prepared by Min in Oct 2010. There are also older sets of slides from 13 May 2005, and Apr 2004.
If you are a student looking for a research project for your graduate studies (GP/MSc), Honors Year (HYP) or undergraduate research opportunity program (UROP) or considering a summer internship, we advise you to look at the slides above, read the following notes and visit our group’s open project listings.
Our current research is sponsored by:
- a MDA grant within the CSIDM Center on Synergy between human computation as language learning and machine translation (joint work the Institute of Automation, Chinese Academy of Sciences)
- a MDA grant within the NExT Center on Extreme Text Search (joint work Tsinghua University, China)
- a NUS GAI grant on mapping the technological and cultural development in Asia (joint work with the Asia Research Institute, NUS)
Temporal Classification
 We seek to improve the interpretation of temporal relationships between interesting units of text, including events and time expressions. Our approach leverages on the inherent structure of English, making use of deeper semantic analysis instead of just surface lexical features. We find that this approach allows us to out-perform other state-of-the-art systems.
We seek to improve the interpretation of temporal relationships between interesting units of text, including events and time expressions. Our approach leverages on the inherent structure of English, making use of deeper semantic analysis instead of just surface lexical features. We find that this approach allows us to out-perform other state-of-the-art systems.
We also study the effectiveness of crowdsourcing in building a corpus annotated with temporal relationships. We are able to identify and isolate instances which are by nature easier to classify. These instances can be skipped over without causing any drop in classifier performance.
The end goal is to be able to get a better understanding of text, and apply this understanding to useful downstream applications such as automatic text summarization.
Deliverables:
Publications:
- Exploiting Discourse Analysis for Article-Wide Temporal Classification
- Improved Temporal Relation Classification using Dependency Parses and Selective Crowdsourced Annotations
Project Staff:
Mobile App Recommendation
 Mobile applications (apps) are soaring in popularity and creating economic opportunities for app developers, companies, and marketers. The selection available in App Stores is growing rapidly as new apps are approved and released daily. While this growth has provided users with a myriad of apps, the sheer number of choices also makes it more difficult for users to find apps that are relevant to their interests.
Mobile applications (apps) are soaring in popularity and creating economic opportunities for app developers, companies, and marketers. The selection available in App Stores is growing rapidly as new apps are approved and released daily. While this growth has provided users with a myriad of apps, the sheer number of choices also makes it more difficult for users to find apps that are relevant to their interests.
Recommender systems that depend on previous user ratings (i.e., collaborative filtering, or CF) can address this problem for apps that have sufficient past ratings. But for apps that are newly released, CF does not have any user ratings to base recommendations on, causing the cold-start problem.
We explore various ways to provide app-recommendations under cold-start scenarios.
Deliverables:
- App Recommendation System
Project Staff:
Automatic Summarization
 SWING: The Summarizer from the Web IR / NLP Group (WING), hence SWING, is a modular, state-of-the-art automatic extractive text summarization system. It produces informative summaries from multiple topic related documents using a supervised learning model. SWING is also the best performing summarizer at the international TAC 2011 competition, getting high marks on the ROUGE evaluation measure.
SWING: The Summarizer from the Web IR / NLP Group (WING), hence SWING, is a modular, state-of-the-art automatic extractive text summarization system. It produces informative summaries from multiple topic related documents using a supervised learning model. SWING is also the best performing summarizer at the international TAC 2011 competition, getting high marks on the ROUGE evaluation measure.
The summarizer is optimized for news articles, and is freely available for download.
Product Review Summarization: Product review nowadays has become an important source of information, not only for customers to find opinions about products easily and share their reviews with peers, but also for product manufacturers to get feedback on their products. As the number of product reviews grows, it becomes difficult for users to search and utilize these resources in an efficient way. In this work, we build a product review summarization system that can automatically process a large collection of reviews and aggregate them to generate a concise summary. More importantly, the drawback of existing product summarization systems is that they cannot provide the underlying reasons to justify users’ opinions. In our method, we solve this problem by applying clustering, prior to selecting representative candidates for summarization.
Metadata-based Webpage Summarization: (Project Duration: June 2003 – December 2004) Search engines currently report the top n documents that seem most relevant to a user’s query. We investigate how to change the structure this ranked list into a more meaningful natural language summary. Rather than just focus on the content of the actual webpages, we examine how metadata can be used to create useful summaries for researchers.
Graphical Models of Summarization: (Joint work with Wee Sun Lee and Hwee Tou Ng). We examine graph based methods to text summarization, with respect to the graph construction and representation of (multidocument) texts and graphical decomposition methods leading to summaries. Unlike previous approaches to graph-based summarization, we devise a graph based approach that creates the graph with a simple model of how an author produces text and a reader consumes it. We are currently applying this work to blog summarization.
Deliverables:
- Open-souce SWING system. Product of Jun Ping Ng, Praveen Bysani, Ziheng Lin.
- SMART – Supervised Categorization of JavaScript using Program Analysis Features. Product of Wei Lu.
- MeURLin: URL based website classification. Poster paper in WWW 2004.
- Welcome Exclusivity Classifier, hosted on sourceforge.net. Product of Edwin Lee.
Publications:
- Product Review Summarization based on Facet Identification and Sentence Clustering (longer version of *, arXiv:1110.1428)
- Product Review Summarization from a Deeper Perspective* (short paper, JCDL’11)
- Exploiting Category-Specific Information for Multi-Document Summarization
- SWING: Exploiting Category-Specific Information for Guided Summarization
Project Staff:
- Praveen Bysani (Spring 2011)
- Min-Yen Kan
- Edwin Lee, alumnus, Automatic metadata extraction for the web (Fall 2003)
- Thiam Chye Lee, alumnus, Multidocument summarization using NLG (Fall 2004)
- Ziheng Lin (Spring 2012; Automatic Text Summarization using a Lead Classifier in Spring 2005 and Spring 2006)
- Wei Lu, alumnus, Multidocument summarization using NLG (Fall 2004)
- Duy Khang Ly
- Alex Ng, alumnus, Automatic metadata extraction for the web (Fall 2003)
- Jun-Ping Ng
- Kazunari Sugiyama
- Yung Kiat Teo, alumnus, Hierarchical Text Segmentation (Fall 2004)
- Eileen Xie, alumnus, URL-based Web Page Classification (Fall 2004)
- Xuan Wang, Blog Summarization (Fall 2007)
Question Answering
 Definitional Question Answering: We explore advanced techniques in definition question answering: soft pattern matching, and boosting of IR recall and precision of extended definition sentences using external web resources and historical query logs. We also explore the construction of fluent definitions using sentence understanding and re-synthesis.
Definitional Question Answering: We explore advanced techniques in definition question answering: soft pattern matching, and boosting of IR recall and precision of extended definition sentences using external web resources and historical query logs. We also explore the construction of fluent definitions using sentence understanding and re-synthesis.
Joint work with the LMS group led by Prof. Tat-Seng Chua
Questiong Answering Framework: QANUS is an abbreviation for “Question-Answering by NUS”, NUS being the abbreviation of the National University of Singapore. QANUS is an open-sourced, information-retrieval (IR) based question-answering (QA) system.
There are 2 key motivating factors behind the development of QANUS. First it is to serve as a framework from which QA systems can be quickly developed. Second it is to act as a baseline system against which QA performance can be easily and reproducibly benchmarked.
Deliverables:
- Open-source QANUS framework
- DefSearch: definition searcher demonstration, based on work in TREC 2003 and a paper in WWW 2004.
- JavaRAP: Lappin and Leass’ pronominal anaphora resolution program, implemented as a Java program. Freely downloadable and installable. Published in LREC 2004.
- Processed Gigaword and AQUAINT corpora. Fully POS tagged and parsed versions of two commonly-used corpora used in TREC research.
- Processed DUC corpus. Canonicalized versions of the 2001-2004 corpus for internal research.
Project Staff:
- Cui Hang (Spring 2003)
- Min-Yen Kan
- Qiu Long (Fall 2003)
- Jun-Ping Ng
Retweet Analysis and Prediction
 What makes a tweet worth sharing? We study the content of tweets to uncover linguistic tendencies of shared microblog posts (retweets), by examining surface linguistic features, deeper parse-based features and Twitterspecific conventions in tweet content.
What makes a tweet worth sharing? We study the content of tweets to uncover linguistic tendencies of shared microblog posts (retweets), by examining surface linguistic features, deeper parse-based features and Twitterspecific conventions in tweet content.
We show how these features correlate with a functional classification of tweets, thereby categorizing people’s writing styles based on their different intentions on Twitter. We find that both linguistic features and functional classification contribute to re-tweeting. Our work shows that opinion tweets favor originality and pithiness and that update tweets favor direct statements of a tweeter’s current activity. Judicious use of #hashtags also helps to encourage retweeting.
Deliverables:
- 860 Annotated Tweets with Functional Category
- Tweets Classification Demo
Publications:
Project Staff:
NUS SMS Corpus
 Short Message Service (SMS) messages are now a ubiquitous form of communication, connecting friends, families and colleagues globally. However, there is precious little corpora with which researchers can study to understand this phenomenon that is in the public domain.
Short Message Service (SMS) messages are now a ubiquitous form of communication, connecting friends, families and colleagues globally. However, there is precious little corpora with which researchers can study to understand this phenomenon that is in the public domain.
We resurrected our earlier project from 2004 for SMS collection in October 2010, reviving it as a live corpus project. The goal is to continually enlarge the corpus, using a array of collection methodologies, leveraging current technology trends. As of January 2013 , we have collected 41980 English SMS messages and 31205 Chinese SMS messages. To the best of our knowledge, it is the largest English and Chinese SMS corpus in the public domain.
Deliverables:
- SMS Corpus
Publications:
Project Staff:
FlashMob – Social Language Learning Application
![]() It is used for assisting people to learn foreign languages through the interactions with the system and other language learners
It is used for assisting people to learn foreign languages through the interactions with the system and other language learners
The FlashMob, flash-based application, is currently available on Facebook and also under the development. It provides functionalities including “make flashcard sets”, “learn languages with flashcards” and “play games”. Users can easily share their action news with friends through Facebook platform.
Deliverables:
Project Staff:
- Aobo Wang
- Jesse Gozali
- Jin Zhao
- Jovian Lin
- Min-Yen Kan
CUBIT
 Cubit is an open-source project, which aims to help professional people organize their publication list and analyze citation distributions. It also designed for people to compare the literature influence of different research groups/centers.
Cubit is an open-source project, which aims to help professional people organize their publication list and analyze citation distributions. It also designed for people to compare the literature influence of different research groups/centers.
Deliverables:
- Coming soon!
Publications:
Project Staff:
Paper-Presentation Alignment
Thousand of papers are published each year, most of which are accessible through electronic libraries and online databases, usually in Portable Document Format (PDF). Scientists also try to present their research findings in the form of slide presentations. These two forms of media contain unique type of information that cannot be combined with each other. It would be much convenient if viewers can read these two versions together and switch between them whenever needed.
The goal of this project is to design a paper-presentation aligner which takes a pair of paper-presentation and generates a map to show which slide is related to which part of the paper. Slides with no text on them and slide which were not extracted directly from the paper content are some issues that we try to address in our alignment system.
Deliverables:
Project Staff:
- Min-Yen Kan
- Bamdad Bahrani
Scholarly Paper Recommendation
Much of the world’s new knowledge is now largely captured in digital form and archived within a digital library system. However, these trends lead to information overload, where users find an overwhelmingly large number of publications that match their search queries but are largely irrelevant to their latent information needs. Therefore, we develop methods for recommending scholarly papers relevant to each researcher’s information needs.
Furthermore, among researchers, junior researhers need to broaden their range of research interests to acquire knowledge, while senior researchers seek to apply their knowledge towards other areas to lead interdisciplinary research. Therefore, we also develop methods for recommending scholarly papers that are serendipitous to each researcher’s research interests.
Deliverables:
Publications:
- Serendipitous Recommendation for Scholarly Papers Considering Relations Among Researchers (short paper, JCDL’11)
- Scholarly Paper Recommendation via User’s Recent Research Interests (JCDL’10)
Project Staff:
Citation Analysis
Researchers have largely focused on analyzing citation links from one scholarly work to another. Such citing sentences are an important part of the narrative in a research article. If we can automatically identify such sentences, we can devise an editor that helps suggest when a particular piece of text needs to be backed up with a citation or not. In terms of this point, we propose a method for identifying citing sentences by constructing a classifier using supervised learning.
Publications:
- Identifying Citing Sentences in Research Papers Using Supervised Learning (CAMP’10)
Project Staff:
- Tarun Kumar
- Kazunari Sugiyama
- Min-Yen Kan
- Ramesh C. Tripathi
Source Code Plagiarism Detection
Existing source code plagiarism systems focus on the problem of identifying plagiarism between pairs of submissions. The task of detection, while essential, is only a small part of managing plagiarism in an instructional setting. Holistic plagiarism detection and management requires coordination and sharing of assignment similarity — elevating plagiarism detection from pairwise similarity to cluster-based similarity; from a single assignment to a sequence of assignments in the same course, and even among instructors of different courses. To address these shortcomings, we have developed Student Submissions Integrity Diagnosis (SSID), an open-source system that provides holistic plagiarism detection in an instructor-centric way.
Deliverables:
SSID: Source Code Plagiarism Detection System and Dataset
Publications:
- Instructor-Centric Source Code Plagiarism Detection and Plagiarism Corpus (ITiCSE’12)
Project Staff:
- Jonathan Y. H. Poon
- Kazunari Sugiyama
- Yee Fan Tan
- Jesse Gozali
- Jun-Ping Ng
- Min-Yen Kan
Mapping the Technological and Cultural Landscape of Scientific Development in Asia
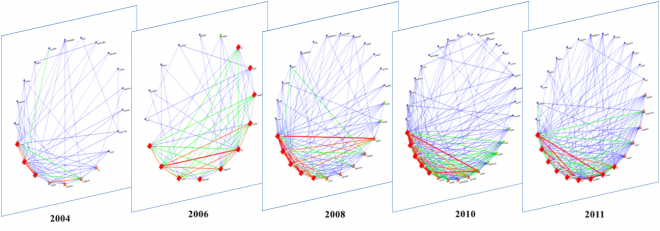 Scientific and technological advancement lay at the heart of any notion of the historical emergence of a Global Asia that extends beyond national or regional borders to encompass rapidly changing worldwide networks of expertise, infrastructure, and research agendas. There is a pressing need to empirically analyze the potential of Big Science research, now the dominant model throughout the region, to truly transform Asian cities into aspiring global command posts of knowledge production. A clear map of these urban centers of innovation and their activities spanning across a multicultural landscape is vital to navigate Singapore’s future.
Scientific and technological advancement lay at the heart of any notion of the historical emergence of a Global Asia that extends beyond national or regional borders to encompass rapidly changing worldwide networks of expertise, infrastructure, and research agendas. There is a pressing need to empirically analyze the potential of Big Science research, now the dominant model throughout the region, to truly transform Asian cities into aspiring global command posts of knowledge production. A clear map of these urban centers of innovation and their activities spanning across a multicultural landscape is vital to navigate Singapore’s future.
This project charts the shifting centers of Big Science research in Asia and their evolving global networks within the context of different understandings of a scientific revival or Renaissance in China, India, Singapore, and the Middle East. The distinctive development pattern of scientific traditions, careers, communities and institutions in each region leading up to the establishment of current large-scale research facilities will be compared. At issue is whether these new hubs anchor the changing shape of global science networks and drive research agendas. A multidisciplinary team of social and computer scientists will also develop an interactive mapping and database system using computerized data-mining to historically track the flow of scientists and their research outputs as “knowledge vectors” along networks of international Big Science facilities.
Deliverables:
- Enlil, a CRF based machine learning system to extract authors and their corresponding affiliaitons from scholarly publications.
- Google Scholar Network Analysis Package (GSNAP) – Scrapes publicly available scholarly publicaitions, facilatates co- authorship network analysis including computation of metrics we have published.
Publications:
The following are our most recent publicaitons. For a complete list of publications please click here.
- Philip S. Cho, Huy Hoang Nhat Do, Muthu Kumar Chandrasekaran, Min-Yen Kan (2013). “Identifying Research Facilitators in an Emerging Asian Research Area: A case study of the Pan-Asian SNP Consortium.” Forthcoming in Scientometrics, Springer.
- Huy Do Hoang Nhat, Muthu Kumar Chandrasekaran, Philip S. Cho, Min-Yen Kan (2013). “Extracting and Matching Authors and Affiliations in Scholarly Documents.” Forthcoming in Proceedings of the 13th annual international ACM/IEEE Joint Conference on Digital Libraries (JCDL ’13). Indianapolis, Indiana, USA. ACM, 2013. [(.pdf) preprint]
Project Staff:
- Philip S Cho
- Muthu Kumar C
- Min-Yen Kan
- Hoang Nhat Huy Do (alumni)
- Bac Vo Sy (alumni)
Popularity-aware Web 2.0 Item Ranking Leveraging User Comments
In this work, we approached the problem of predicting the future popularity of general Web 2.0 items (e.g. image/video/singer in Flickr/YouTube/Last.fm). The problem of predicting items’ popularity is useful and benefits many tasks, such as ranking for time-sensitive queries, online advertising, caching strategies and so on. However, it is challenging both due to its dynamic nature and lacking of visiting histories, which are difficult and costly to obtain externally. Instead of tackling the problem as a traditional time series prediction task, in this work, we propose to use the affiliated user comments to enable the prediction. A novel temporal bipartite user-item ranking algorithm that models users, items and comments is proposed. Extensive experiments of three datasets (Flickr, YouTube and Last.fm) show the effectiveness and robustness of the proposed approach.
Publications:
- Coming soon…
Project Staff:
- Xiangnan He
- Ming Gao
- Min-Yen Kan
Older Projects
Web Query Analysis
Web queries are often dense and short, but they often have distinct purposes. In our work, we examine how to automatically classify web queries using only the simple, lightweight data of query logs and search results. In comparison, most existing automatic methods integrate rich data sources, such as user sessions and click-through data. We believe there is more untapped potential for analyzing and typing queries based on deeper analysis of these simple sources.
Project Staff
- Min-Yen Kan , Project Lead
- Viet Bang Nguyen, Macro and Microscopic Query Analysis for Web Queries (Spring 2006)
- Hoang Minh Trinh, Implementing Query Classification (Fall 2007)
LyricAlly: Lyric Alignment
Joint work with Wang Ye and Haizhou Li.
 Popular music is often characterized by sung lyrics and regular, repetitive structure. We examine how to capitalize on these characteristics along with constraints from music knowledge to find a suitable alignment of the text lyrics with the acoustic musical signal. Our previous work showed a proof of concept of aligning lyrics to popular music using a hierarchical, musically-informed approach, without the use of noisy results from speech recognition. Later results tried to improve alignment to the per-syllable level using an adapted speech recognition model, initially trained on newswire broadcasts.
Popular music is often characterized by sung lyrics and regular, repetitive structure. We examine how to capitalize on these characteristics along with constraints from music knowledge to find a suitable alignment of the text lyrics with the acoustic musical signal. Our previous work showed a proof of concept of aligning lyrics to popular music using a hierarchical, musically-informed approach, without the use of noisy results from speech recognition. Later results tried to improve alignment to the per-syllable level using an adapted speech recognition model, initially trained on newswire broadcasts.
However, these approaches are slow and require offline computation and cannot be run in real-time. In recent work, we have been examining whether we can do away with intense computation by using self-similarity to align the lyrics and music directly without explicit multimodal processing.
Deliverables (Excluding Publications)
- Minh Thang Luong’s RepLyal lyric alignment demo / home page
Project Staff
- Min-Yen Kan , Project Co-Lead
- Denny Iskandar, alumnus
- Minh Thang Luong, Using Self-Similarity in Lyric Alignment for Popular Music (Spring 2007)
Advanced OPACs
Project Duration: 4 years, ending July 2007. Continuing work without formal funding. Joint work with Danny C. Poo.
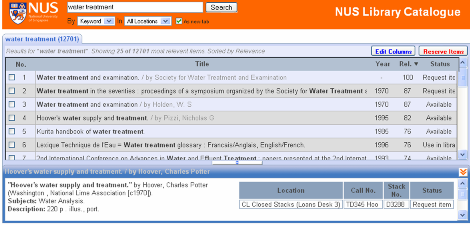
When library patrons utilize an online public access catalog (OPAC), they tend to type very few query words. Although it has been observed that patrons often have specific information needs, current search engine usability encourages users to underspecify their queries. With an OPAC’s fast response times and the difficulty of using more advanced query operators, users are pushed towards a probe-and-browse mode of information seeking. Additionally, patrons have adapted (or forced to adapt) to OPACs and give keywords as their queries, rather than more precise queries. As a consequence, the search results often only approximate the patron’s information need, missing crucial resources that may have been phrased differently or offering search results that may be phrased exactly as wanted but which only address the patron’s information need tangentially.
One solution is to teach the library patron to use advanced query syntax and to formulate more precise queries. However, this solution is both labor-intensive for library staff and time-intensive for patrons. Furthermore, different OPACs support different levels of advanced capabilities and often represent these operators with different syntax. An alternative solution that we propose is the use of advanced query analysis and query expansion. Rather than change the behavior of the patron, a system can analyze their keyword queries to infer more precise queries that uses advanced operators when appropriate. To make these inferences, the system will not only rely on logic but also will dynamically access both a) historical query logs and b) the library catalog to assess the feasibility of its suggestions.
The proposed research will target three different types of query rewriting/expansion: 1) correction of misspellings, 2) inferring the relationships between a query’s noun and noun phrases, and 3) inferring intended advanced query syntax. The realization of these techniques will allow patrons to continue using OPACs by issuing simple keyword searchers while benefiting from more precise querying and alternative search suggestions that would originate from the implemented system.
In our current work we have examined how to re-engineer and design the User Interface to better supoort the actual information seeking methods used by library patrons. Jesse has re-engineered the work and has incorporated our own NUS OPAC as well as Colorado State University’s OPAC results into his tabbed, overview+details framework. If you have a library catalog with MARC21 results that can be exported we can wrap our UI around your database. Contact us for more information.
Project Deliverables (excluding publications)
- Jesse Gozali’s OPAC interface for [ NUS ] [ Colorado State University ]
- Long Qiu’s report on the Namekeeper (author spelling correction) system.
- List of misspelled titles in the LINC OPAC catalog system (over 1.2K misspellings), reported to Libraries
- Prototype spelling correction and morphology system (linc2.cgi, and its past incarnation mirror.cgi)
- Notes/Slides from past meetings with NUS Library staff:
[ 16 June 2004 ] [ 11 May 2005] [ 26 Aug 2005]
Project Staff
- Min-Yen Kan, Project lead
- Jin Zhao, Query Analysis and typing (Spring 2005)
- Malcolm Lee, OPAC UI (Spring 2005)
- Tranh Son Ngo, alumnus, Systems programmer
- Kalpana Kumar, Ranked spelling correction and Advanced Query Analysis (Spring 2004 and Spring 2006)
- Jesse Gozali, An AJAX interface for the LINC system (Spring 2006)
- Siru Tan, alumnus, Morphology (Spring 2004)
- Meichan Ng, alumnus, Phrase structure (Spring 2004)
- Roopak Selvanathan, alumnus, programmer
- Long Qiu, alumnus, author spelling correction
Scenario Template Generation
A Scenario Template is a data structure that reflects the salient aspects shared by a set of events, which are similar enough to be considered as belonging to the same scenario. The salient aspects are typically the scenario’s characteristic actions, the entities involved in these actions and the related attributes. Such a scenario template, once populated with respect to a particular event, serves as a concise overview of the event. It also provides valuable information for applications such as information extraction (IE), text summarization, etc.
Manually defining scenario template is expensive. In this project, we aim to automatize the template generation process. Sentences from different event reports are broken down into predicate-argument tuples which are clustered semantically. Then salient aspects are generalized from big clusters, respectively. For this purpose, features we investigate include word similarity, context similarity, etc. The resulting scenario template is not only a structured collection of salient aspects as a manual template is, but also a information source that other NLP systems can refer to for how these salient aspects are realized in news reports.
Stay tuned for a corpus release of newswire articles that Long has compiled for use in the Scenario Template tasks.
Project Staff
- Min-Yen Kan, Project lead
- Long Qiu (Spring 2003)
Web-based disambiguation of digital library metadata
Joint work with A/P Dongwon Lee at Pennsylvania State University.
As digital libraries grow in size, the quality of the digital library metadata records become an issue. Data entry mistakes, string representation differences, ambiguous names, missing field data, repeated entries and other factors contribute to errors and inconsistencies in the metadata records. Noisy metadata records make searching difficult, and possibly result in certain information not being found at all, causing an under-count or over-count and distorting aggregate statistics, and decrease the utility of digital libraries in general.
In this project, we concentrate on using the Web to aid the disambiguation of the metadata records. This is because sometimes the metadata records itself contains insufficient information, or the required knowledge is very difficult to mine. However, the richness of the Web, which represents the collective knowledge of the human population, often provides the answer instantly when suitable queries are presented to a search engine. As search engine calls and web page downloads are processes that are expensive on time, any Web-based disambiguation algorithm must be able to scale up to large number of records.
Project Staff
- Min-Yen Kan, Project lead
- Yee Fan Tan (Fall 2005)
Phrase Based Statistical Machine Translation
Joint work with Haizhou Li.
Due to the nature of the problem, machine translation provides an interesting playground for the implementation of statistical approach. The problems in machine translation are rendered from the ambiguity in several level starting from the surface until the semantic level, where in isolation itself poses a great challenge. In this project, our pursuit is to advance the performance of reordering model. Reordering model attempts to restructure the lexically translated sentence to the correct target language’s ordering. In particular, we examine reordering centered around function words. This is motivated by observation that phrases around function words are often incorrectly reordered. By modelling reordering patterns around function words, we hope to capture prominent reordering patterns in both the source and target languages.
Project Staff
- Min-Yen Kan, project lead
- Hendra Setiawan
Focused crawling
Project Duration: Continuing.
Web crawling algorithms have now been devised for topic specific resources, or focused crawling. We examine the specialized crawling of structurally-similar resources that is used as input to other projects. We examine how to devise trainable crawling algorithms such that they “sip” the minimal amount of bandwidth and web pages from a site by considering using context graphs, negative information, web page layout, and URL structure as evidence.
To motivate the crawling algorithm design, we concentrate on the collection of four real-world problems: topical page collection, the collection of song lyrics, scientific publications and geographical map images.
Project Deliverables (excluding publications)
- Maptlas: A collection of map images culled from the web.
Project Staff
- Min-Yen Kan, Project lead
- Abhishek Arora: Map Spidering and Browsing User Interface (Summer 2005)
- Hoang Oanh Nguyen Thi, alumnus, Publication Spiderer (Spring 2004)
- Litan Wang, alumnus, music lyrics spider (Fall 2004)
- Vasesht Rao, alumnus, Map tiling and spidering (Fall 2004)
- Fei Wang, Non-photograph image categorization (Fall 2004 and Spring 2005)
- Xuan Wang , Augmenting Focused Crawling using Search Engine Queries (Spring 2006)
Domain-Specific Research Digital Libraries

Despite the enormous success of common search engines for general search, when it comes to domain-specific search, their performance is often compromised due to the lack of knowledge of (and hence support to) the entities and the users in the domain. In our project, we choose to tackle this problem in the domain of mathematics and healthcare. Our ultimate goal is to build a system which is able to 1) automatically categorize and index domain-specific resources, 2) handle the special representation of domain-knowledge in the resources, and 3) provide better search support and workflow integration.
Project Deliverables (excluding publications)
- dAnth: digital anthologies mailing list – a clearinghouse for researchers dealing with text conversion, citation processing and other scaling issues in digital libraries.
- ForeCite: Web 2.0 based citation manager a la Citeulike, Citeseer, Rexa.
- SlashDoc: A Ruby on Rails new media knowledge base for research groups.
- SlideSeer: A digital library of aligned slides and papers.
- ParsCit: citation parsing using maximum entropy and global repairs.
Project Staff
- Min-Yen Kan, Project lead
- Dang Dinh Trung: TiddlWiki for scholarly digital libraries (Spring 2007)
- Ezekiel Eugene Ephraim: Presentation summarization, alignment and generation (Spring 2005)
- Guo Min Liew, Visual Slide Analysis (Spring 2007)
- Jesse Gozali, ForeCite integration lead (summer project, Summer 2007)
- Hoang Oanh Nguyen Thi, alumnus, Publication Spiderer (Spring 2004)
- Yong Kiat Ng, Maximum Entropy Citation Parsing with Repairs (Spring 2004)
- Emma Thuy Dung Nguyen, Automatic keyword generation for academic publications (Spring 2006)
- Thien An Vo, Support for annotation of scientific papers (Spring 2004)
- Tinh Ky Vu, Public-domain research corpora gatherer (Fall 2004) and Academic Research Repository (Spring 2005)
- Yue Wang, Presentation summarization, alignment and generation (Spring 2006)
- Jin Zhao, Math and healthcare IR (Fall 2007)
Lightweight NLP
Project Duration: Continuing.
Joint work with Dr. Samarjit Chakraborty.
 For embedded systems with constrained power and CPU resources, how should NLP and other machine learning tasks be done. We investigate how different combinations of features and learners can affect machine learned NLP tasks on embedded devices with respect to time, power and accuracy.
For embedded systems with constrained power and CPU resources, how should NLP and other machine learning tasks be done. We investigate how different combinations of features and learners can affect machine learned NLP tasks on embedded devices with respect to time, power and accuracy.
Project Staff
- Min-Yen Kan, Project lead
- Ziheng Lin, Summer Project (Summer 2007)
PARCELS: Web page division and classification
Project Duration: December 2003 – July 2005. Completed.
Web documents that look similar often use different HTML tags to achieve their layout effect. These tags often make it difficult for a machine to find text or images of interest.
Parcels is a backend system [Java] designed to distinguish different components of a web site and parse it into a logical structure. This logical structure is independent of the design/style of any website. The system is implemented using a co-training framework between two independent views: a lexical module and a stylistic module.
Each component in the structure will be given a tag revelant to the domain they are classified under.
Project Deliverables (excluding publications)
- PARCELS toolkit, hosted on sourceforge.net.
- Similar document similarity (integrated within the PARCELS toolkit.
Project Staff
- Min-Yen Kan, Project lead
- Chee How Lee, alumnus, programmer
- Aik Miang Lau, alumnus, Advancing PARCELS (Fall 2004)
- Sandra Lai, alumnus, PARCELS Web logical structure parser (Fall 2003)
SMS text input
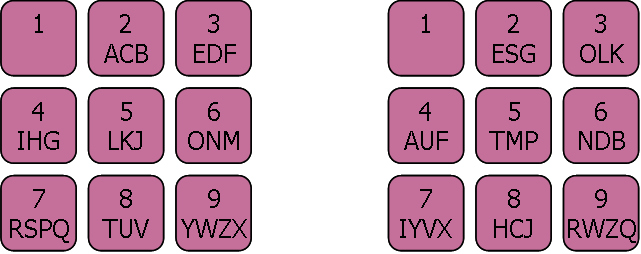
Project Duration: December 2003 – July 2005
Short message service (SMS) is now a ubiquitous way of communicating. The numeric keys of the phone are mapped to the letters on the phone. This project examines methods for predictive text entry techniques and user interface design for doing the text entry.
We are working on extend the collection of a publicly available corpus of SMS messages and use them to compile statistics for subsequent analysis. We examine predictive text entry of completion of one word, two or more words, as well as models and data structures for computing completion efficiently for individual hand phones (per-phone modeling) as well as on a corpus wide basis (per-language modeling).
Project Deliverables (excluding publications)
- NUS SMS Corpus – A collection of over 10,000 Short Message Service (SMS) messages.
- Shortform / Longform Codec
Project Staff
- Min-Yen Kan, Project lead
- Mingfeng Lee, Shortform Longform SMS Codec (Fall 2004)
- Yijue How, alumnus, Analysis of SMS input efficiency (Fall 2003)
Light verb constructions
Project Duration: May 2004 – July 2005.
A light verb construction (LVC) is a verb-complement pair in which the verb has little lexical meaning and much of the semantic content of the construction is obtained from the complement. Examples of LVCs are “make a decision” and “give a presentation”, and these pose challenges for natural language processing and understanding. In this project, we investigate methods to identify LVCs from a corpus, as well as recognizing linguistic features of LVCs.
Project Staff
- Min-Yen Kan, Project lead
- Yee Fan Tan
- Hang Cui