Current Projects
2024
Visualising Large Language Model Activations
This project aims to create a visualiser for neural network architectures, especially the basic transformer. [More]
2023
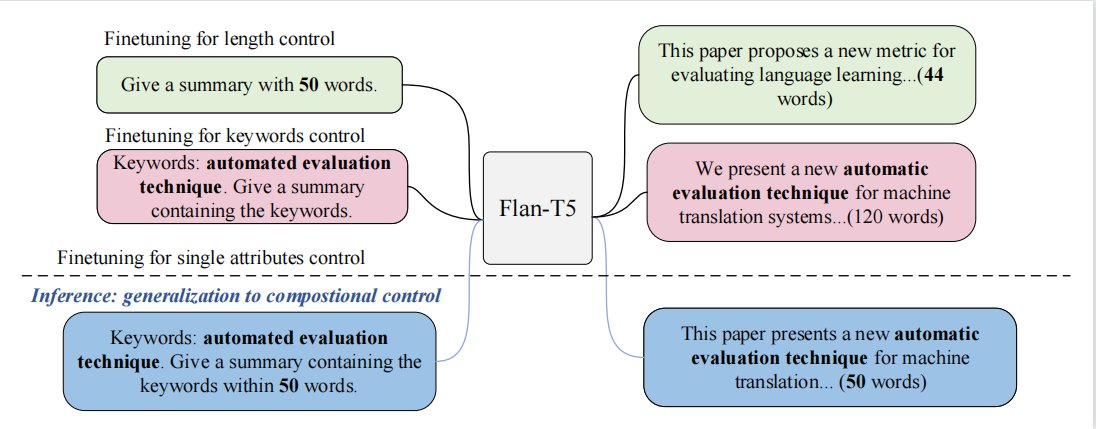
Compositional Controlled Summarization
This project introduces a toolkit for controlled summarization of scientific documents, featuring its ability to manage multiple attributes concurrently. [More]

Edited Media Understanding
This project aims to detect the differences between a pair of images in the domain of media manipulation, while also deducing the implications of these alterations. [More]

Discourse and Language Models
This project investigates improving language models’ discourse comprehension, employing behavioral tests for model fidelity, increasing verifiability through exact memory, and utilizing distant supervision for surpassing traditional training objectives. [More]
![]()
Computational “Emojistics”
This project seeks to improve NLP systems’ comprehension and utilization of emojis by exploring emoji representation and integration in textual communication. [More]
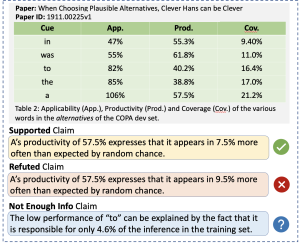
Scientific Table Fact Checking
This project introduces a novel dataset SCITAB, comprising 1.2K challenging scientific claims accompanied by original scientific tables, which aims to address the limitations in current benchmarks such as crowd-sourced claims and a lack of quantitative experimental data representation. [More]
2021-2022
Adversarial Factorization Machine: Towards accurate, robust, and unbiased recommenders
The model-based collaborative filtering (CF) such as factorization machine (FM) were proposed to approach recommendation as a representation learning problem. Though FM takes rich features including user-profiles and item attributes into consideration, due to the high sparseness of the data in the recommendation system, the precision of individual feature embedding is limited and vulnerable to adversarial perturbations. Moreover, data in the real world is largely unbalanced, leading to the biased recommendation result to long-tailed groups. In this project, we propose an Adversarial Factorization Machine (AdvFM), a novel method that learns adversarial perturbation levels given the signal strength distribution of user and item attributes during adversarial training. [More]

Dialogue State Tracking in Low Resource Setting
Understanding the current state of a dialogue is extremely critical in building powerful conversational recommendation systems. However, the biggest problem encountered while developing such systems is lack of labelled data as with every new domain, new slots-value pairs come and thus a labelling cost. Moreover, manual labelling of states in a new domain is costly and time-consuming. Therefore, we need to resort to low resource techniques. [More]

Scientific Document Processing
Nowadays many research fields conduct empirical studies based on real-world datasets. There is a lack of a proper mechanism to find papers using certain datasets or identify datasets used in certain papers. Identifying important aspects of scientific publications such as dataset mentions is important for many downstream tasks like indexing, search among many. In social science, the dataset forms an integral aspect of the study, however, it is referred to in many different surface forms. In this project, we explore different approaches of identifying such mentions of datasets in papers i.e. mention extraction, and classifying the mentions to the refereed dataset i.e. dataset discovery. [More]

Task-Oriented Dialogue Augmentation
This is study aims to improve the current state in task-oriented dialogue augmentation through exploring dialogue-level transformations rather than the usual word or sentece level tranformations used so far in the literature. [More]

Comparison of Products via Conversational Systems
This project aims to help buyers to compare products via a conversational system. [More]

Deep Question Generation
This project aims to generate human-like deep questions. [More]
Analysing Vision+Language neural networks
This project aims to analyse recent Vision+Language neural networks based on the Transformer architecture, drawing on methods traditionally used for studying human language processing. [More]
2020

An Artificial Intelligence-based system for boosting career prospects:
Neural Sign Language Recognition & Translation:
This project aims to use scientific methods to do neural sign language recognition & translation. We work on extending an open-source library like transformers to include state of the art sign language recognition methods. We also intend to improve the state of art in continuous sign language recognition.[More]
Mining Service Contributions from Call For Paper and Journal Websites
This project aims to enhance a system that mines and ranks the service contributions of Computer Science researchers and institutions. The project uses multiple NLP models or methods to improve the accuracy and scoping of the system. [More]
Word Sense Disambiguation: A Co-operative Game Theoretic Approach
This project aims to model the problem of Word Sense Disambiguation using a Cooperative Game Theory approach in formulating preference relations among the corpus, type of coalitions formed and finding whether the outcomes under given coalition structures are optimal in resolving the ambiguity. [More]
Course Recommendation System:
In NUS alone, total undergraduate enrollment increased 10% to 31,257 in 5 years’ time from 2015 to 2019. This number is expected to increase further in the future. Similar trend is observed across the world. Among all the possible obstacles these students might face, module selection is definitely one of them. This project aims to build a module recommender to ease the stress about module selection. [More]
2019

Mining Service Contributions from Call-for-papers:
This project aims to document the service contributions of Computer Science researchers. Our system automatically crawls for relevant pages in CS Conference Call-for-paper websites to performs the extraction of information such as the details of organizers and key participants. [More]

Investigating Instructor Intervention in MOOC Discussion Forums:
This project aims to design predictive models to identify important threads from MOOC discussion forums. It prompts MOOC instructors, through a dashboard, with a forum triage, on when and how to intervene in discussion forums so that good pedagogical practices can be scaled in the context of MOOCs. [More]

Discourse Parsing for Multi-party Dialogues:
Discourse parsing is a task which can parse discourse structure in text automatically, including identifying structure and labeling discourse relations. Most existing research of discourse parsing is about PDTB and RST-DT. However, models that trained in written datasets maybe not appropriate for spoken language and dialogues. Different from previous work on the news or monologue dataset, there is little research focuses on discourse parsing on multi-party dialogues. There are two sub-tasks in this project: edges detection and relation classification. In this project, we explore different methods for detecting discourse dependencies and discourse relations in multi-party dialogues. [More]
Visual Recommendation for Academic Collaboration:
With the exploding increase in conferences and scientific community data and it’s metadata, it has become complex and tedious to explore the whole community and choose research collaborators in academia and beyond, be it inter or intra domain. By exploiting academic graphs, we address this problem of academic collaboration recommendation and give visual analysis along with the recommendation. [More]

Citation Context and Provenance Scope Detection:
Reference in papers sometimes refer to specific sections of the paper. A citation can apply just to a specific clause, sentence or even large tracts of a paper. In the project, we would like to know the scope of the specific section that is being referred to. Drawing on ParsCit, a library created by WING-NUS, we wish to create a model to 1) find the citation maker, and 2) learn the scope of the citation; that is, how many words/sentences are related to the actual cited work. [More]
Word Inception from Word Embeddings:
Word embeddings have played a great role in improving the current state of the art in many tasks in NLP and IR. However, we can also leverage their role as representational models of meaning to work on tasks that immediately deal with the semantics of words. In this project, we employ word and character embeddings to identify existing words and reverse-engineer new words based on their definitions. [More]
2018

Conversational Recommendation:
Recommendation system has been widely used in web platforms including content providers and E-commerce companies. Traditional recommendation system has difficulty making good recommendations when the information about the given user is insufficient, it is usually addressed as the Cold Start problem. Furthermore, user’s intent and interest can be varied with time. Therefore, it would be greatly helpful if we can make recommendations interactively with a given user, and it is very natural to do it in a dialogue system between the agent and the user.(Photo Credit: weheartit@daughterofdragon)[More]
2017

Credibility Analysis in Health Communities:
There has been an increasing number of people asking for medical advice or health-related opinions online. In the context of healthcare and medicine, inaccurate information from untrustworthy members may cause serious hazards and must be taken with caution. This project aims to analysis credibility of user statements in health communities, considering features specific to online communities to generate useful insights. [More]
Trend Analysis and Prediction in Scholarly Documents:
With increasing volume of scientific documents added existing archives every day, it is difficult yet crucial to track the emergence of the research topics and its impact. This project aims to address some of the issues of analysis of big scholarly corpus and other contemporary signals to generate useful insights. [More]

Mobile App Recommendation:
This project aims to build recommendation systems for App Stores. The model is developed from a graph-based approach, and it utilises Twitter information which can precede formal user ratings in app stores, as well as version information which is specific to mobile apps. [More]

MOOC Wikification:
This project aims to build a system which is able to identify the resources mentioned and referenced in the discussion forums of MOOC platforms and link to the actual location automatically. It provides learners the ability to combine all resources in a more convenient way. [More]

NER In Legal Domain:
This project is in collaboration with INTELLLEX (a tech start-up for law), and aims to increase the precision of existing Named Entity Recognition systems. While not restricting on the types of people, location, etc, the project has been extended to the scope of Legal terms. [More]

A Web Based Dashboard for MOOC Instructors:
This project is proposed in assistance of the Instructor Intervene in MOOC Discussion Forums [link], and aims to build a system which takes in generic forum threads (from Coursera, edX, etc), and outputs the threads in the order of importance such that instructors are able to intervene on time. [More]

Verb Duration Discovery:
This project aims to discover the relationships between verbs and durations. So if given a verb and a situation, we can predict how long the action will last. For example, given a verb “eat”, a situation “I eat sandwich”, we can predict the action “eat” will last for a couple of minutes. [More]

Snippet Generation for MOOC Discussion Forums:
This project aims to identify relevant sentences that are significant in MOOC Discussion Forum threads to generate a summary. [More]

NUS MOOC Corpus: Crowdsourcing annotations to study instructor intervention:
This project proposes to annotate a large corpus of instructor-intervened threads using AMT2, enabling supervised machine learning algorithms to automatically identify interventions that promote student learning. [More]
2016

Implicit Discourse Relation Recognition:
This project aims to leverage on both traditional feature-based and deep learning approaches to improve the recognition performance of PDTB style implicit discourse relation such that it can be made viable for real world applications. [More]

Coursera Crawler:
A crawler for the Coursera website to get the discussion forum data. This crawler depends on PhantomJS to simulate the login process and PycURL to get the target data via hidden APIs. It can be easily extended to get information dynamically displayed on the webpage apart from the discussion forums. [More]
2015

Scholarly Paper Recommendation:
This project aims to propose methods for recommending scholarly papers relevant to a specific researcher’s interests and needs. At the same time, the methods provide serendipitous suggestions as well, such that researchers are able to reach out to other disciplines and areas. [More]
2013
ParsCit
The ParsCit project aims to build a system for two tasks: 1) reference string parsing (citation parsing, citation extraction), and 2) logical structure parsing of scientific documents. It is architected as a supervised machine learning procedure that uses Conditional Random Fields as its learning mechanism. [More]
2012

Source Code Plagiarism Detection:
This project aims to build a system which leverages the performance of code plagiarism detection models. Apart from detecting similar code pairwise, the system is able to identify cluster similarity among a group submission, and a Student Submissions Integrity Diagnosis (SSID) system has been developed. [More]
2011

Citation Analysis:
This project aims to build a system which helps to identify citing sentences in research papers by constructing a supervised learning classifier. With the correct classification of those sentences, it is able to provide an assisting editor to indicate whether a specific piece of text needs to be backed up by citation. [More]
Proposed Projects:
You’ll find a list of projects proposed by WING members and if you are interested, please contact the respective person in charge for more details.

Keyphrase Extraction:
Keyphrases are words that capture the main topics of a document. Extracting high- quality keyphrases can benefit various natural language processing (NLP) applications: in text summarization, keyphrases are useful as a form of semantic metadata indicating the significance of sentences and paragraphs, in which they appear; in both text categorization and document clustering, keyphrases offer a means of term dimensionality reduction, and have been shown to improve system efficiency and accuracy; and for search engines, keyphrases can supplement full-text indexing and assist users in formulating queries. [More]
For projects which are earlier than 2011, please refer to here.